Introduction
In the era of digital transformation, the sheer volume of data generated by businesses and individuals is staggering. From social media interactions and online transactions to sensor data from IoT devices, the world produces an estimated 2.5 quintillion bytes of data every day. Managing, storing, and analyzing this massive influx of information is a monumental challenge and is where Hadoop comes into play.
Definition
Hadoop big data analytics is the process of utilizing the Hadoop ecosystem, which includes technologies like MapReduce and HDFS (Hadoop Distributed File System), to analyze massive amounts of data. Data-driven decision-making is made possible by its ability to help organizations effectively store, evaluate, and extract insights from large datasets. Because Hadoop’s distributed computing framework allows for parallel processing, it is perfect for managing a variety of data kinds and carrying out intricate analytical jobs at scale.
Understanding Hadoop
Hadoop, developed by the Apache Software Foundation, is an open-source framework designed to store and process large datasets across distributed computing clusters. Its architecture is based on two core components:
Hadoop Distributed File System (HDFS): A scalable, fault-tolerant storage system that enables data to be distributed across multiple nodes.
MapReduce: A programming model that processes data in parallel across the distributed nodes.
The Hadoop ecosystem’s data processing and analytics capabilities are further enhanced by tools like Hive, Pig, HBase, and Spark in addition to these fundamental elements.
Scalability and Cost-Effectiveness
One of the most compelling reasons for Hadoop’s widespread adoption is its scalability. Traditional data storage systems struggle to handle the exponential growth of data, often requiring costly hardware upgrades. Hadoop, on the other hand, leverages clusters of commodity hardware to store and process data, significantly reducing costs.
- Horizontal Scaling: Hadoop allows organizations to scale their infrastructure horizontally by adding more nodes to the cluster rather than upgrading existing hardware. This approach is both cost-efficient and flexible.
- Open-Source Advantage: Being open-source, Hadoop eliminates licensing costs, making it an attractive option for businesses of all sizes.
Distributed and Fault-Tolerant Architecture
Hadoop’s distributed architecture is a game-changer for processing large datasets. Unlike traditional systems that rely on a central server, Hadoop distributes data across multiple nodes, enabling parallel processing. This improves fault tolerance in addition to speeding up data processing.
- Replication: HDFS automatically replicates data across multiple nodes, ensuring data availability even if a node fails.
- Task Resilience: If a node becomes unavailable during a MapReduce operation, Hadoop automatically reassigns the task to another node, maintaining uninterrupted data processing.
Handling Diverse Data Types
Modern data analytics involves dealing with structured, semi-structured, and unstructured data. Hadoop’s flexibility in handling diverse data types makes it a vital tool for big data analytics.
- Structured Data: Relational databases and spreadsheets.
- Semi-structured Data: JSON, XML, and log files.
- Unstructured Data: Text files, images, videos, and social media content.
Hadoop’s ability to process these data types without extensive preprocessing reduces the time-to-insight and enhances decision-making.
Speed and Performance with Hadoop Ecosystem Tools
While Hadoop’s MapReduce framework provides robust processing capabilities, it’s often considered slower compared to modern tools. However, the Hadoop ecosystem includes tools like Apache Spark that significantly boost speed and performance.
- Apache Spark Integration: Spark’s in-memory processing capabilities complement Hadoop’s storage and batch processing features, delivering faster data analytics.
- Hive and Pig: These tools simplify querying and data manipulation, making Hadoop more accessible to users without advanced programming skills.
Use Cases of Hadoop in Big Data Analytics
Hadoop’s versatility makes it applicable across various industries, driving innovation and operational efficiency. Here are some notable use cases:
- Retail and E-commerce: Hadoop enables personalized marketing by analyzing customer preferences, purchase history, and browsing behavior.
- Healthcare: Hospitals use Hadoop to analyze patient records, medical imaging, and genomic data for better diagnostics and treatment planning.
- Financial Services: Hadoop helps in fraud detection by analyzing transaction patterns in real-time.
- Telecommunications: Telecom companies leverage Hadoop to optimize network performance and customer experience.
- Social Media Analysis: Platforms use Hadoop to analyze user interactions and trends for targeted advertising and content recommendations.
Challenges and Solutions
While Hadoop is a powerful framework, it’s not without its challenges. Understanding these issues and their solutions can help organizations maximize its potential.
Steep Learning Curve: The complexity of Hadoop’s ecosystem can be overwhelming.
- Solution: Investing in training and leveraging user-friendly tools like Hive can mitigate this challenge.
Latency in Real-Time Processing: Hadoop’s batch processing is not ideal for real-time analytics.
- Solution: Integrating Hadoop with real-time processing tools like Apache Kafka can bridge this gap.
Security Concerns: Hadoop lacks robust built-in security features.
- Solution: Employing third-party security solutions and implementing access controls can enhance data protection.
Emerging Trends in Hadoop Big Data Analytics
Integration with Cloud Platforms:
Hadoop is increasingly being integrated with cloud platforms to enhance scalability and flexibility. Cloud-based Hadoop solutions, like Amazon EMR and Google Cloud Dataproc, are enabling businesses to process massive datasets without investing heavily in on-premises infrastructure.
Real-Time Data Processing:
Real-time analytics is a growing trend, with frameworks like Apache Kafka and Apache Flink complementing Hadoop. Businesses may process and analyse streaming data using these solutions, resulting in immediate insights and speedier decision-making.
Adoption of Hybrid Architectures:
Organizations are embracing hybrid architectures that combine Hadoop with data warehouses and other big data tools. This approach ensures optimized storage and processing for structured, semi-structured, and unstructured data.
Enhanced Security Features:
As data breaches become more common, enhanced security features in Hadoop, like fine-grained access control and data encryption, are becoming critical. Tools like Apache Ranger and Knox are helping ensure secure data management and compliance.
Machine Learning Integration:
Machine learning (ML) workflows are increasingly powered by Hadoop. With platforms like TensorFlow and MLlib being integrated into Hadoop ecosystems, businesses can perform advanced predictive analytics on big data.
The Future of Hadoop in Big Data Analytics
As big data continues to evolve, so does Hadoop. Emerging trends and technologies are shaping its future:
Cloud Integration: The adoption of cloud-based Hadoop solutions like Amazon EMR and Google Cloud Dataproc enables scalability and flexibility.
AI and Machine Learning: Integrating Hadoop with AI/ML frameworks allows organizations to derive deeper insights from their data.
Edge Computing: Combining Hadoop with edge computing technologies can enable faster analytics for IoT applications.
Improved User Experience: Tools and interfaces are becoming more intuitive, reducing the learning curve and broadening Hadoop’s appeal.
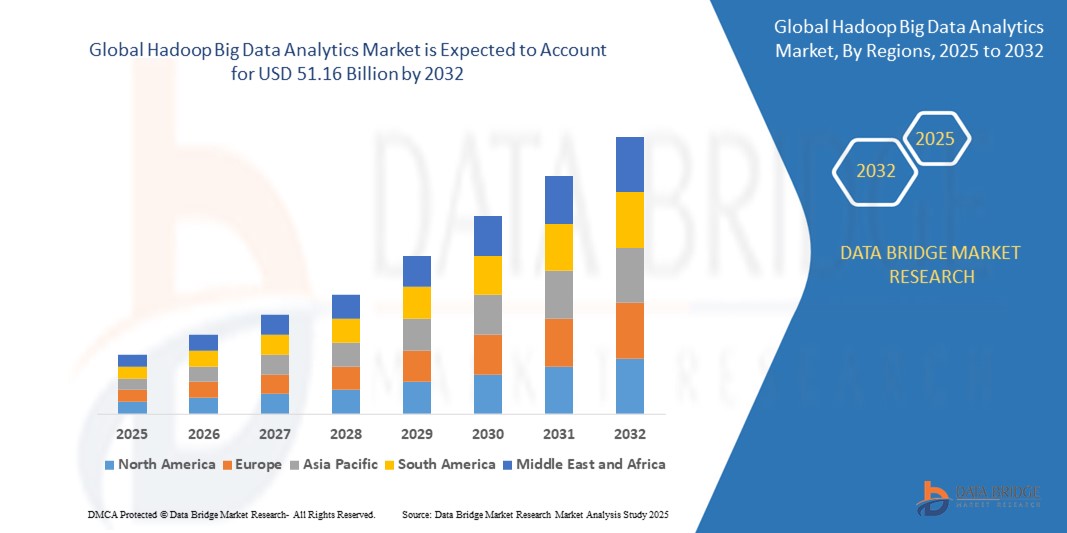
Hadoop Big Data Analytics Market Growth Rate
With a projected value of USD 10.83 billion in 2023, the global Hadoop big data analytics market is expected to grow at a compound annual growth rate (CAGR) of 18.83% from 2024 to 2031, reaching USD 43.04 billion.
Read More: https://www.databridgemarketresearch.com/reports/global-hadoop-big-data-analytics-market
Conclusion
Hadoop has revolutionized the way organizations manage and analyze big data. Its scalability, cost-effectiveness, and ability to process diverse data types make it an indispensable tool in today’s data-driven world. By addressing its challenges and leveraging its ecosystem, businesses can unlock the full potential of their data, driving innovation and competitive advantage.